Abstract
More and more RDF data is exposed on the Web via SPARQL endpoints and analyzed using SPARQL aggregate queries. As data volumes grow, standard SPARQL query processing techniques can no longer support sufficiently fast query response times. For this, relational databases use materialized views, which precompute aggregate query results and reuse these for query answering, but relational techniques do not support RDF specifics such as data incompleteness, the schemaless nature of RDF, and the need to support implicit (derived) information.
This paper proposes an RDF-based approach to selecting an appropriate set of materialized RDF views and using these for effective SPARQL query rewriting, which handles these RDF specifics. Specifically, we propose an RDF-specific cost model, a view definition syntax, and algorithms for view selection and query rewriting. The experimental evaluation shows that the approach can improve query response time by more than an order of magnitude and handles RDF specifics well.
Authors: Dilshod Ibragimov, Katja Hose, Torben Bach Pedersen, and Esteban Zimanyi
SSB Queries
SSB defines 13 queries. They represent 4 "prototypical" queries with different selectivity factors.
A brief description of the queries is given in a table below.
We converted all 13 queries defined into SPARQL
| Query Prototypes | Query No | Query Parameters for Various Selectivities |
|---|
| Prototype 1. Amount of revenue increase that would have resulted from eliminating certain company-wide discounts. |
Q1 |
Discounts 1, 2, and 3 for quantities less than 25 shipped in 1993 |
| Q2 |
Discounts 1, 2, and 3 for quantities less than 25 shipped in 01/1993 |
| Q3 |
Discounts 5, 6, and 7 for quantities less than 35 shipped in week 6 of 1993 |
| Prototype 2. Revenue for some product classes, for suppliers in a certain region, grouped by more restrictive product classes and all years. |
Q4 |
Revenue for 'MFGR#12' category, for suppliers in America |
| Q5 |
Revenue for brands 'MFGR#2221' to 'MFGR#2228', for suppliers in Asia |
| Q6 |
Revenue for brand 'MFGR#2239' for suppliers in Europe |
| Prototype 3. Revenue for some product classes, for suppliers in a certain region, grouped by more restrictive product classes and all years. |
Q7 |
For Asian suppliers and customers in 1992-1997 |
| Q8 |
For US suppliers and customers in 1992-1997 |
| Q9 |
For specific UK cities suppliers and customers in 1992-1997 |
| Q10 |
For specific UK cities suppliers and customers in 12/1997 |
| Prototype 4. Aggregate profit, measured by subtracting revenue from supply cost. |
Q11 |
For American suppliers and customers for manufacturers 'MFGR#1' or 'MFGR#2' |
| Q12 |
For American suppliers and customers for manufacturers 'MFGR#1' or 'MFGR#2' in 1997-1998 |
| Q13 |
For American customers and US suppliers for category 'MFGR#14' in 1997-1998 |
LUBM Queries
We defined in SPARQL 6 analytical queries involving grouping over several classification dimensions. We use COUNT aggregation in all queries.
These queries aggregate over number of courses offered by departments, number of courses taken by students, number of graduate courses in each department,
number of courses taught by professors in each department, etc.
A brief description of the queries is given in a table below.
| Query No | Query Description |
|---|
| Q1 |
Count student courses: the number of courses students have taken, classified by the student’s department, university, and advisor |
| Q2 |
Count faculty member courses: the number of courses faculty members teach, classified by the department which they are a member of and the university the department is in |
| Q3 |
Count research assistant courses: the number of courses research assistants have taken, classified by the department they work for, the university of that department, and their advisor. |
| Q4 |
Count graduate courses taught by professors : the number of graduate courses professors teach, classified by the professor's department and the university for which she works. |
| Q5 |
Count department courses: the number of courses offered by department, classified by the department and the university of the department. |
| Q6 |
Count the number of final exams a faculty member should grade if every course's final evaluation is an exam, classified by faculty, her department, the university for which she works. |
Datasets
The SSB benchmark provides a data generator that generates relational data. It generates data for 4 dimensions (Parts, Customers, Suppliers, and Dates) and transactional data (observations).
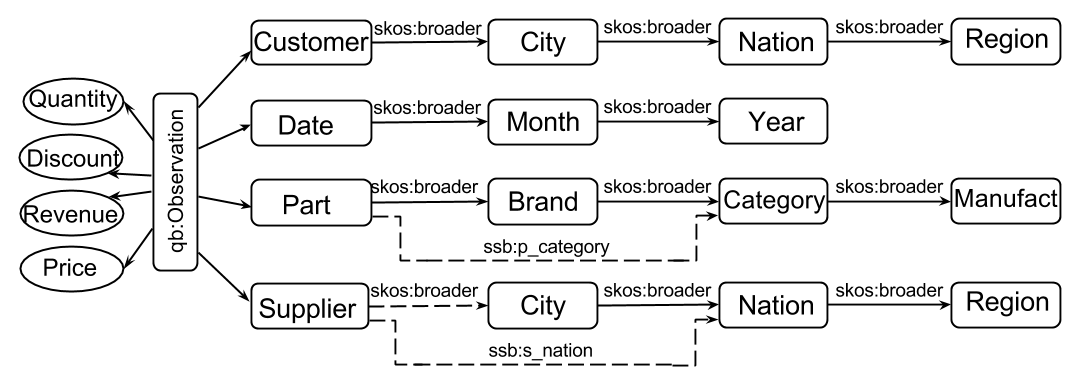
We then translated the datasets into the RDF multidimensional representation (QB4OLAP) introducing incompleteness to this dataset as well, as illustrated in the figure below.
In this dataset, a lineorder item is represented as an observation described by dimensions, where a subject (observation) is connected to objects (dimensions) via certain predicates.
Every connected dimension object is, in turn, defined as a path-shaped graph. Hierarchies in dimensions are connected via the skos:broader predicate.
Measures (represented as ovals) are connected directly to observations. We changed the data generator so that approx. 30% of the information that relates suppliers to their corresponding
cities in the Supplier dimension (and parts to their brands in the Part dimension) is missing. Instead, we connected suppliers with missing city information directly to their
respective nations (ssb:s\_nation) and parts with missing brand information we connected directly to the next level in the hierarchy -- categories (ssb:p\_category).
Thus, in the roll-up path Supplier -> City -> Nation -> Region the City level is incomplete. The Part dimension is affected in the level Brand (Part -> Brand -> Category -> Manufacturer).
In our experiments, we used different scaling factors (1,2,3) to obtain datasets of different sizes. Observations and all dimensional data are stored in separate graphs --
one for each dimension (parts, customers, suppliers, and dates) and one for observations.
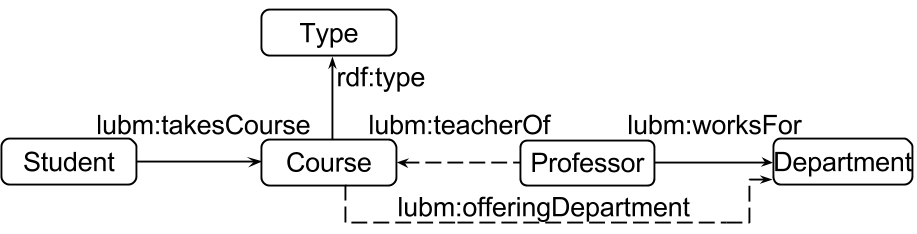
LUBM features an ontology for the university domain; it creates synthetic OWL data scalable to an arbitrary size. The dataset describes universities, departments, students,
professors, publication, courses, etc. We decided to build our data cube and corresponding queries on the information related to courses. In particular, we are interested in
knowing the number of courses offered by departments, the type of the courses, the number of students taking courses, etc.
To introduce incompleteness in the data we changed the data generator so that approx. 30% of the information that relates staff to courses is missing. Instead, we introduced
information about the department that offers these courses (lubm:offeringDepartment). In such settings, counting the number of courses offered by departments becomes
more challenging since the roll-up path Course -> Staff -> Department needs to be complemented by the roll-up path Course -> Department and the aggregation of courses by
Department cannot be answered by the results of the aggregation by Staff. A simplified schema of the data structure is presented in the figure below.